
以下のDAマップではさらに、諸課題の今後の動向を「自動化の境界線」に沿って示している。これは、人間に適した意思決定と機械に適した意思決定を分ける境界を推定したものだ。
右上がりの線で示された自動化の境界線は、現時点で許容されている予測可能性とエラーの境界線を表している。エラーごとの損失が高いほど、自動化における高度な予測可能性が要求される。図中の湾曲した境界線は、直線の境界線よりも自動化への障壁が高いことを表している。
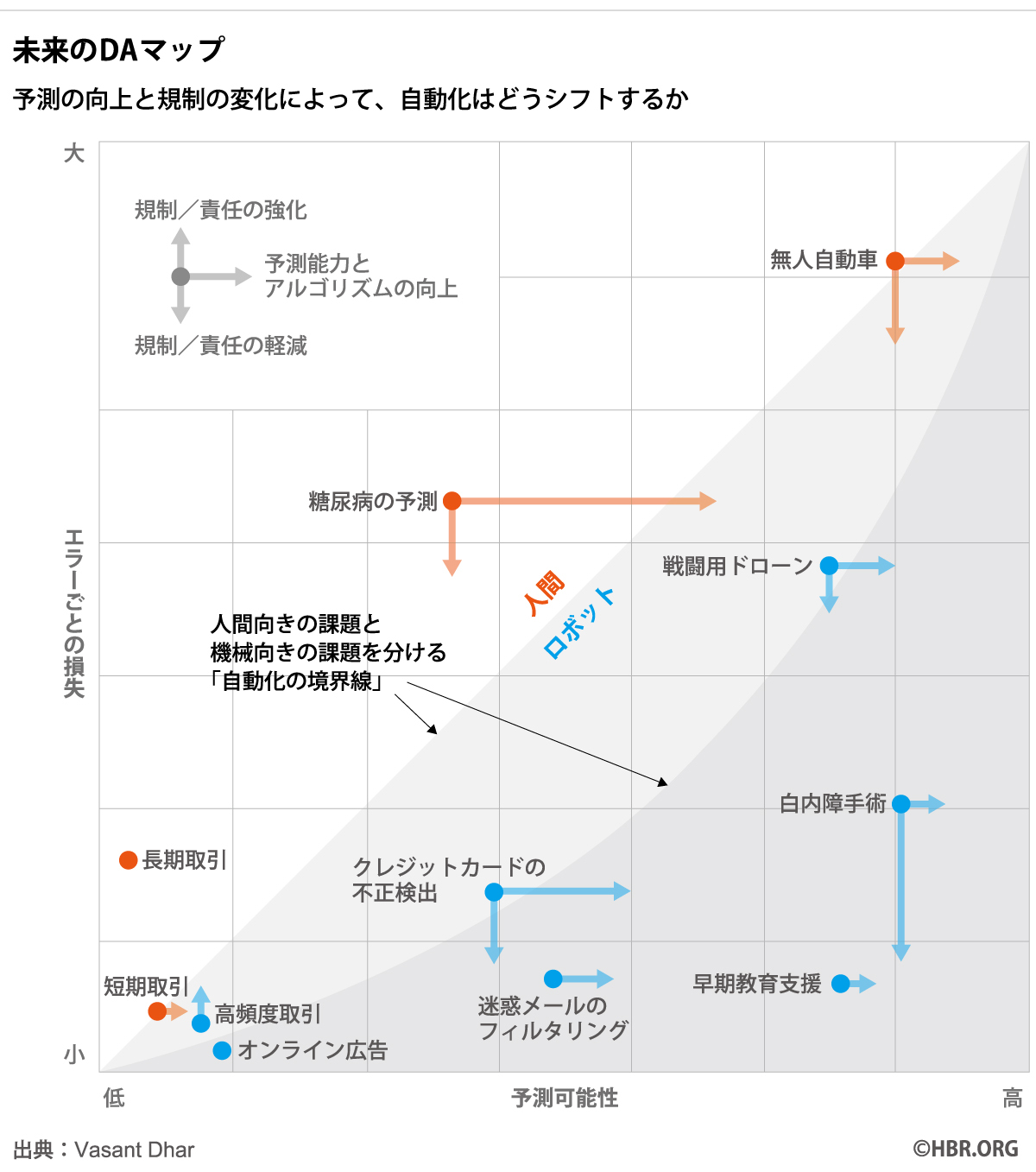
自動化の境界線の下側には、高頻度取引やオンライン広告などがあり、すでにかなり自動化されている。エラーごとの損失よりも、信頼性と拡張性が高いことのメリットが勝るからだ。これに対して、糖尿病の予測は境界線の上側にある。現在の最も優れた糖尿病予測システムですら、誤検出と検出漏れがあまりに多い。機械に完全に任せるには損失が高すぎるわけだ。そのため、患者の糖尿病リスクの判定には依然として医師が介在している。
一方で、遺伝子情報やその他の個人データが利用できるようになれば、糖尿病の予測精度は劇的に向上する可能性もある(オレンジ色の長い右矢印)。あるいは、信頼のおける医療ロボットが登場するかもしれない。
予測可能性とエラーごとの損失が変化することで、その課題がロボットの領域に加わったり、そこから外れたりする。たとえば、図で「人間」の領域にある無人自動車は、性能が向上してより快適に利用できるようになれば、責任を制限する法律が導入・採択されることも考えられる。すると、エラーごとの損失を減らす保険の市場ができるかもしれない(下方のロボット領域に入る)。
企業のマネジャー、投資家、規制当局、政策立案者などは、意思決定の自動化をめぐる問いに答えを出す際に、DAマップを用いることができる。自動化の取り組みの優先順位をつけるときにもマップは役立つ。また、機械が最低限の事前プログラミングによって必要な専門知識をデータから学習できる課題はどれか、そしてエラーの損失が低いものはどれかも明らかにできる。
データから学習する機械を導入するうえで最大の困難は、初めて遭遇する「特殊なケース」に対処する際の不確実性であろう。たとえばグーグルの無人自動車が、障害物によって些細な事故を起こしたようなケースである。人間は奇異・新規の出来事に対して、本能的に「常識」を適用する。だが機械の場合、そこで何を学習していかに対応するかは、きわめて不確実だ。特殊なケースに際しては深刻な結果を引き起こしかねない。
特殊な状況における機械の不確実性が大きければ大きいほど、人々は決定を機械に任せたがらず、人間の進化、本能、常識に根差した馴染み深い判断手法を選ぶだろう。
一方、社会にとって最も悩ましい懸念は、自動化によって人間の仕事が大量に廃れる可能性だ。1960年代初頭、ノーベル経済学賞受賞者のハーバート・サイモンはこう予測した。ビジネスにおけるプログラム可能な意思決定の多くは、20~30年のうちに自動化されるだろうが、自動化が「人を食い物にする」という心配は見当違いだ、と。
これまでのところ、サイモンの予測はどちらの面でも当たっている。自動化は、人間のために新たな仕事とライフスタイルを生み出し続けている。しかし、目と耳を持ち、文字を読み、論理的に判断できる新種の機械は、人間の仕事をもっと創出するのだろうか。それとも奪うほうが多いのか。現時点ではまだ見えていない。
HBR.ORG原文:When to Trust Robots with Decisions, and When Not To May 17, 2016
■こちらの記事もおすすめします
デジタル時代のM&Aは「自社への取り込み」から「共創」へ
バサント・ダール(Vasant Dhar)
ニューヨーク大学スターン・スクール・オブ・ビジネスの教授。情報システム学を担当。『ビッグデータ』誌の編集長。




![H.ミンツバーグ経営論[増補版]](https://dhbr2.ismcdn.jp/mwimgs/8/7/135w/img_871cd4da49e5d4f957c01d18842ab79034921.jpg)









